
문자열 리스트를 한번 만들어 봅시다. 방법은 다양합니다.
첫 번째 방법입니다. 리스트를 먼저 생성하고, 요소들을 'add( )'로 채우는 방법입니다.
// 1ST. list를 먼저 만들고 add로 요소 삽입 (크기가 정해져있지 않다.)
private static List<String> makingListV1() {
List<String> list1 = new ArrayList<>();
list1.add("apple");
list1.add("banana");
list1.add("castle");
return list1;
}간단한 코드이지만, 요소가 늘어날 때마다 무작정 코드를 써 내려가기에는 양을 무시하지 못할 것입니다.
우리는 좀 더 간단한 코드를 스트림을 공부할 때 사용해 왔습니다!
// add보다는 더 빠르게 생성이 가능 but, 크기가 정해져있기때문에, 새 요소를 추가하거나 삭제가 불가능.
private static List<String> makingListV2() {
List<String> list2 = Arrays.asList("apple", "banana", "castle");
System.out.println(list2);
list2.set(0, "Apple");
System.out.println("수정 : " + list2);
list2.add("Daddy"); // UnsupportedOperationException
System.out.println("요소 추가 : " + list2);
return list2;
}단 한 줄로 리스트의 생성이 가능합니다! 하지만 이 코드의 문제점이 있습니다.
바로 요소 수의 변동이 없어야 한다는 것입니다.
이 코드의 경우에는, 리스트의 크기를 정하고 만들었기 때문에, 요소의 갱신은 가능하나, 요소를 추가하거나, 삭제할 수 없습니다. ('String []' 배열을 생각합시다.)
만약 요소를 추가하거나 삭제하는 경우 'UnsupportedOperationException' 예외를 던지게 됩니다.

다들 하나씩 부족해 보이는 방법들입니다.
자바 9에서는 컬렉션 팩토리 메서드를 제공해 보다 쉽게 컬렉션을 만들 수 있습니다!
컬렉션 생성
1. List 팩토리
간단하게 'List.of( )'를 이용해 리스트를 만들 수 있습니다.
private static void makingListV4() {
List<String> list = List.of("apple", "banana", "castle");
list.set(0, "Apple"); // UnsupportedOperationException 예외 발생
list.add("dad") // UnsupportedOperationException 예외 발생
}하지만, 다른 방법에 비해 확장성은 더욱 떨어집니다. 왜냐하면 이는 요소의 수정도, 추가도 불가능하기 때문입니다.
(다른 컬렉션 팩토리도 마찬가지.) 만약 리스트 요소를 바꿔야 한다면, 새로 생성하는 방법밖에는 없습니다.
컬렉션 팩토리의 경우 컬렉션이 의도치 않게 변하는 것을 막고 싶을 때, Null을 금지할 때를 위한 간단한 구현 방식입니다!
Plus. 오버 로딩과 가변 인수
List.of를 입력하면 수많은 오버 로딩과, 가장 상단에 존재하는 가변 인수를 볼 수 있습니다. (Set, Map 역시 모두 적용)
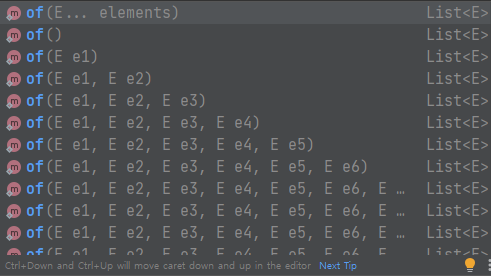
가변 인수의 경우 파라미터가 10개를 넘어갈 때 사용됩니다. 가변 인수는 추가 배열을 할당해서 리스트로 감싸기 때문에 배열 할당, 초기화, GC 비용을 추가적으로 지불해야 합니다.
파라미터가 10개를 넘어가지 않는 경우에는 고정된 파라미터 오버 로딩을 이용해서 이러한 추가적인 비용을 지불하지 않아도 됩니다.
2. Set 팩토리
private static void makingSetV1() {
Set<String> set = Set.of("apple", "banana", "castle");
set.set(0, "Apple"); // UnsupportedOperationException 예외 발생
set.add("dad") // UnsupportedOperationException 예외 발생
}'List.of'와 같다고 보시면 됩니다. 추가적으로 Set의 기본적은 특징(요소의 순서 X, 중복 허용 X)은 그대로 따라갑니다.
3. Map 팩토리
맵의 파라미터는, 키와 값이 필요합니다.
첫 번째 방법으로는 'Map.of'를 이용해 키와 값을 번갈아가며 만드는 것입니다.
private static void makingMapV1() {
Map<String, Integer> intOfStr = Map.of("apple", 10, "banana", 5, "castle", 1);
System.out.println(intOfStr);
}'Map.of'는 특이하게 'List.of'와 'Set.of'과 달리 가변 인수가 없습니다. 대신 'Map.ofEntries'에 가변인수가 존재합니다.
그렇기 때문에 'Map.of'는 10개 이하의 요소를 만들 때만 사용하고, 그 이상의 맵을 만드는 경우라면 'Map.ofEntries'를 사용합시다!
private static void makingMapV2() {
Map<String, Integer> intOfStr = Map.ofEntries(
Map.entry("apple", 10),
Map.entry("banana", 5),
Map.entry("castle", 1));
System.out.println(intOfStr);
}'Map.ofEntries'의 경우에는 'Entry <K,V>'를 인수로 받습니다. 이는 'Map.entry( )'를 통해 생성합니다.
컬렉션 처리
1. List, Set 처리
보통 컬렉션의 처리는 동기화를 주의해야 합니다
private static List<String> removeStartingNumber(List<String> list) {
for (String s : list) {
if (Character.isDigit(s.charAt(0))) {
list.remove(s);
}
}
return list; // ConcurrentModificationException 발생
}
// removeStartingNumber을 분해해보면...
private static List<String> removeStartingNumber(List<String> list) {
for (Iterator<String> iterator = list.iterator(); iterator.hasNext();){ // 반복은 iterator
String str = iterator.next();
if (Character.isDigit(str.charAt(0))) {
list.remove(str); // 요소 삭제는 list
}
}
return list;
}이 코드의 경우 질의는 'iterator' 객체가, 요소의 삭제는 'list' 객체가 맡고 있기 때문에 동기화의 문제가 발생합니다.
그렇기 때문에 객체를 하나로 통일을 하거나, synchronized를 사용해야 합니다.
private static List<String> removeStartingNumberV3(List<String> list) {
for (Iterator<String> iterator = list.iterator(); iterator.hasNext();){
String str = iterator.next();
if (Character.isDigit(str.charAt(0))) {
iterator.remove();
}
}
return list;
}'iterator' 객체가 질의와 삭제 모두 맡고있기 때문에, 동기화 문제를 해결할 수 있게 됩니다.
이렇게 동기화 문제를 간단하게 해결할 수 없을까에 대한 해답을 JAVA8에서 내놓았습니다.
removeIf(Predicate <? super E> filter)
'Predicate'를 만족하는 요소를 제거하는 메서드입니다. 'List', 'Set' 모두 사용 가능합니다.
private static List<String> removeStartingNumberV4(List<String> list) {
list.removeIf(str -> Character.isDigit(str.charAt(0)));
return list;
}위에서 고민한 문제들을 정말 간단하게 해결할 수 있습니다.
replaceAll(UnaryOperator <E> operator)
'UnaryOperator' 함수를 이용해 요소를 바꾸는 기능입니다. 'List'에서 사용할 수 있습니다.
private static void replaceToUpperCaseV1(List<String> list) {
list.stream().map(str -> Character.toUpperCase(str.charAt(0)) + str.substring(1))
.collect(Collectors.toList())
.forEach(System.out::println);
}'replaceToUpperCaseV1' 코드는 'collect(toList)'를 이용해 스트림에서 새 문자열 컬렉션을 만드는 방식입니다.
기존의 리스트를 수정하고 싶다면, 'ListIterator.set'을 이용해야 합니다.
private static void replaceToUpperCaseV2(List<String> list) {
for (ListIterator<String> iterator = list.listIterator(); iterator.hasNext();) {
String code = iterator.next();
iterator.set(Character.toUpperCase(code.charAt(0)) + code.substring(1));
}
}이를 더 간단하게 표현한 것이 바로 'replaceAll( )'입니다!
private static void replaceToUpperCaseV3(List<String> list) {
list.replaceAll(code -> Character.toUpperCase(code.charAt(0)) + code.substring(1));
}
sort(Comparator <? super E> c)
'Comparator'에 맞게 정렬하는 기능입니다. 'List'에서 사용할 수 있습니다.
이 세 메서드들의 특징은 새로운 컬렉션을 생성하는 것이 아닌, 기존의 컬렉션을 바꾸는 것입니다.
2. Map 처리
1) forEach(BiConsumer <? super K,? super V> action)
키와 값을 인수로 받는 'BiConsumer'를 이용하면 'forEach( )'를 통해 더욱 쉽게 Map을 반복할 수 있습니다.
private static void howOldV1(Map<String, Integer> map) {
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String name = entry.getKey();
Integer age = entry.getValue();
System.out.println(name + "는 " + age + "살 입니다.");
}
}
private static void howOldV2(Map<String, Integer> map) {
map.forEach((name, age) -> System.out.println(name + "는 " + age + "살 입니다."));
}
2) 정렬
| 메서드 | 설명 |
| 'comparingByKey' | Key를 기준으로 정렬 |
| 'comparingByValue' | Value를 기준으로 정렬 |
3) getOrDefault(Object key, V defaultValue)
지정된 키가 매핑되는 값을 반환하거나 이 맵에 키에 대한 매핑이 없는 경우 'defaultValue'를 반환합니다. 주로 'NullPointerException'을 방지하기 위해서 이를 사용합니다.
첫 번째 파라미터에는 검색할 Key값을, 두 번째 파라미터에는 맵에 키가 존재하지 않는 경우 반환하는 값을 입력합니다.
추가적으로 기본 구현은 이 메서드의 동기화 또는 원자성 속성에 대해 보장하지 않습니다. 원자성 보장을 제공하는 모든 구현은 이 메서드를 재정의하고 동시성 속성을 문서화해야 합니다.
4) 계산
computeIfAbsent(K key, Function <? super K,? extends V> mappingFunction)
Key에 매핑된 값이 없거나 Null인 경우 제공된 함수를 이용해서 값을 계산 후 입력합니다.
추가적으로 계산된 값이 Null인 경우 Null을 반환합니다.
computeIfPresent(K key, BiFunction <? super K,? super V,? extends V> remappingFunction)
지정된 키의 값이 존재하고 null이 아닌 경우 제공된 함수를 이용해 새로 계산해 매핑을 시도합니다.
추가적으로 함수가 null을 반환하면 매핑이 제거되고, 함수 자체에서 (확인되지 않은) 예외가 발생하면 현재 매핑은 변경되지 않은 상태로 유지됩니다.
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
지정된 키에 현재 매핑된 값(현재 매핑이 없는 경우 null)을 제공된 함수를 이용해 새로 계산해 매핑을 시도합니다.
5) 합치기
두 맵을 합치는 기능입니다.
void putAll(Map <? extends K,? extends V> m)
지정된 맵에서 이 맵으로 모든 매핑을 복사합니다(선택적 작업). 작업이 진행되는 동안 지정된 맵이 수정되면 이 작업의 동작이 정의되지 않습니다. 추가적으로 중복되는 키가 있는 경우 오류가 발생합니다. (이를 위해 merge를 사용합니다.)
merge(K key, V value, BiFunction <? super V,? super V,? extends V> remappingFunction)
조금 더 유연하게 합치기 위해서 사용됩니다. 지정된 키가 아직 값과 매핑되어 있지 않거나 null이면, 지정된 값과 연결하고, 만약 key 값이 중복되는 경우 제공된 함수를 이용해 새롭게 연산한 값을 매핑합니다. 이 방법은 키에 대해 매핑된 여러 값을 결합할 때 사용할 수 있습니다.
3. ConcurrentHashMap 처리
ConcurrentHashMap은 기존의 HashMap과 달리 동시성을 반영하는 최신 기술입니다. 따라서 동시 추가, 갱신 작업이 가능합니다. (동기화된 HashTable에 비해 I/O 연산이 월등함)
'ConcurrentHashMap'는 'Stream'과 비슷한 연산을 지원합니다.
| 종류 | 설명 |
| forEach | 키, 값 연산(forEach) / 키만 연산(forEachKey) / 값으로 연산(forEachValue) / Map.Entry 연산(forEachEntry) |
| reduce | 키, 값 연산(reduce) / 키만 연산(reduceKeys) / 값으로 연산(reduceValues) / Map.Entry 연산(reduceEntries) |
| search | 키, 값 연산(search) / 키만 연산(searchKeys) / 값으로 연산(searchValues) / Map.Entry 연산(searchEntries) |
병렬성 기준값
이 연산들은 병렬성 기준값(THRESHOLD)을 지정해야 합니다.
| 기준값 | 연산 |
| 맵의 크기 < 기준값 | 순차적 연산을 실행 |
| 기준값을 1로 지정 | 공통 스레드 풀을 이용해 병렬성을 극대화 |
| Long.MAX_VALUE를 기준값으로 설정 | 한개의 스레드로 연산을 실행 |
자원 활용 최적화가 되어있지 않다면, 기준값 규칙을 따르는 것을 권장합니다.
기본형 특화
추가적으로 박싱 언박싱을 위한 기본형 특화가 존재합니다. (끝에 To+타입 입력)
ex: reduceValuesToInt, reduceKeysToLong
계수
맵의 매핑 개수를 반환하는 'mappingCount' 메서드를 제공합니다. 기존의 'size( )' 대신 'mappingCount' 메서드를 사용하는 것이 좋은데, 그래야 매핑의 개수가 int의 범위를 넘어서는 이후 상황을 대처할 수 있기 때문입니다.
'JAVA > 모던 자바 인 액션' 카테고리의 다른 글
| 모던 자바 인 액션 20. 새로운 날짜와 시간 API (0) | 2021.09.17 |
|---|---|
| 모던 자바 인 액션 19. Optional (0) | 2021.09.16 |
| 모던 자바 인 액션 15. 병렬처리(2) - 포크/조인 (0) | 2021.08.22 |
| 모던 자바 인 액션 14. 병렬처리(1) - 병렬 스트림 조건 (0) | 2021.08.21 |
| 모던 자바 인 액션 13. 스트림을 이용한 데이터 수집(2) (0) | 2021.08.20 |